What is JASPAR?
JASPAR is a regularly maintained open-access database that stores manually curated transcription factor (TF) binding profiles as position frequency matrices (PFMs). PFMs summarize occurrences of each nucleotide at each position in a set of observed TF-DNA interactions. PFMs can be transformed to probabilistic or energistic models to construct position weight matrices (PWMs) or position-specific scoring matrices (PSSMs), which can be used to scan any DNA sequence to predict TF binding sites (TFBSs). The JASPAR database provides TFBSs predicted using the profiles in the CORE collection.
Since 2026, JASPAR has also stored interpretable deep learning models designed to predict transcription factor binding preferences.
In both cases, the selected motifs are manually curated. Specifically, our curators assess the quality of the motif and search for an orthogonal publication that provides support to the motif as the bona fide motif recognized by the TF of interest (e.g., a motif found in ChIP-seq peaks looks similar to one found by SELEX-seq). The PubMed ID associated with the orthogonal support is provided in the TF profile metadata.
JASPAR is the only database with this scope where the data can be used with no restrictions (open source). For a comprehensive review of models and how they can be used, please see the following reviews
JASPAR collections
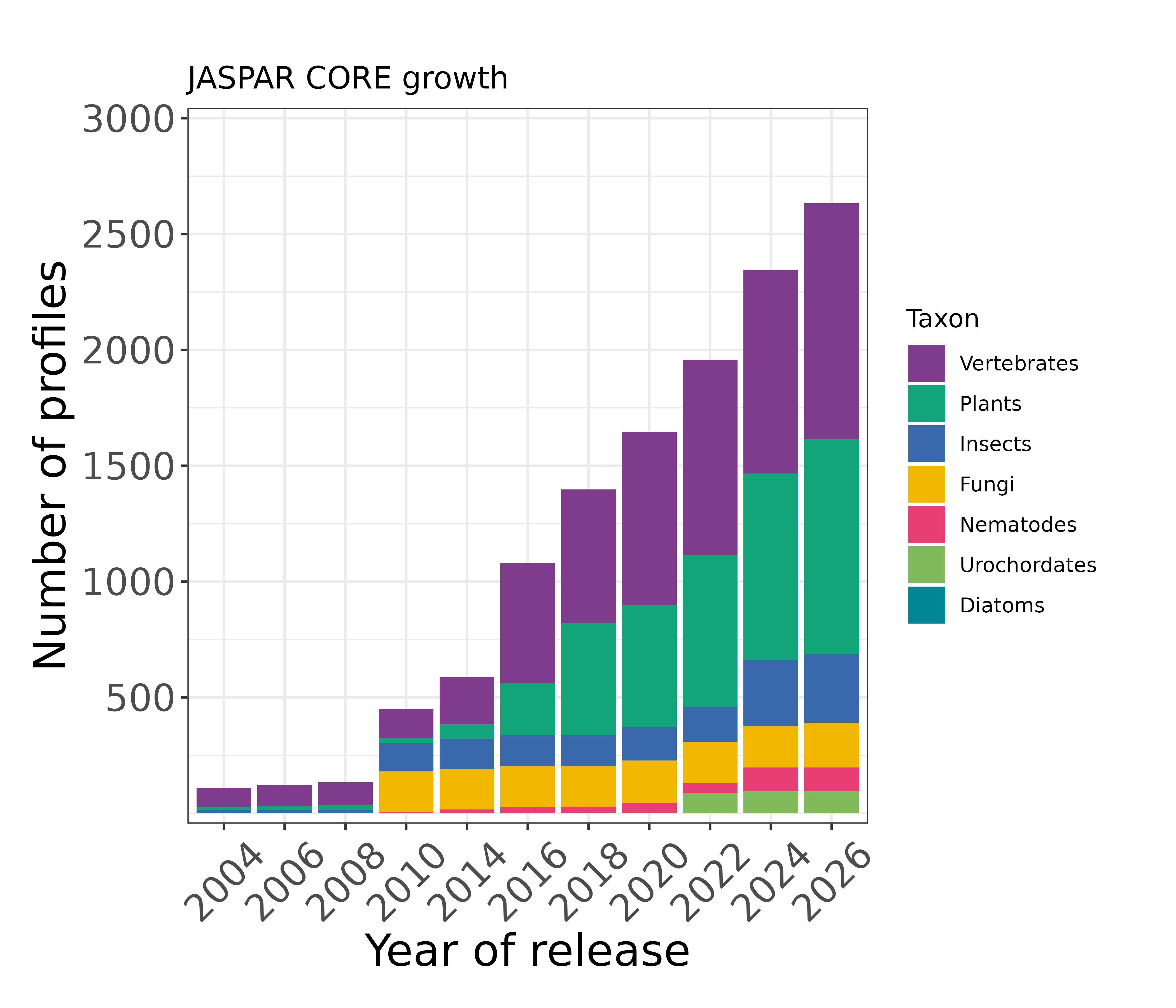
The JASPAR CORE database contains a curated, non-redundant set of profiles, derived from published collections of experimentally defined transcription factor binding sites for eukaryotes. JASPAR is committed to providing open data access and non-redundant, high-quality binding profiles.
When should it be used? When seeking models for specific factors or structural classes, or if experimental evidence is paramount.
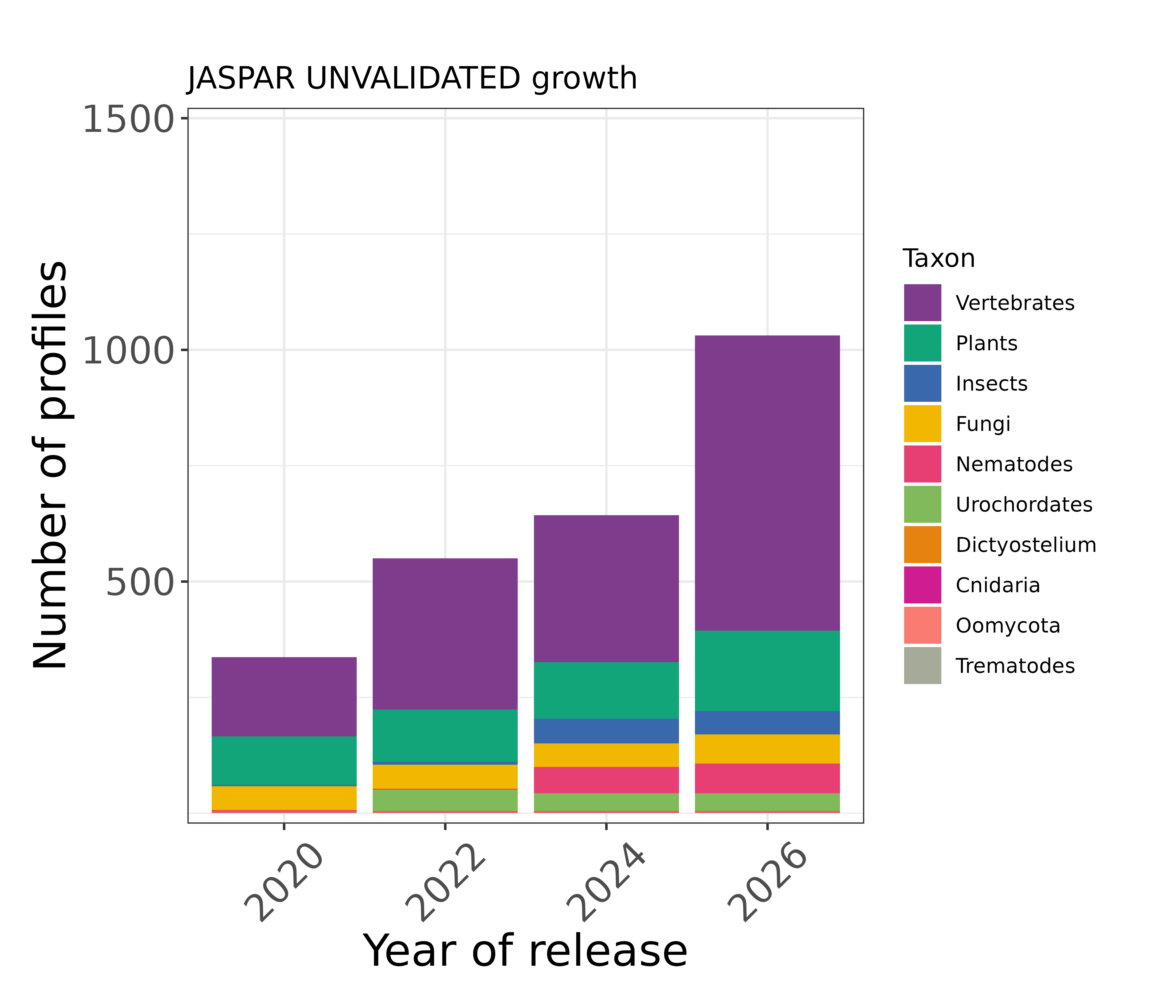
These profiles are considered unvalidated because our curators were unable to find any orthogonal support in the existing literature. We encourage the community to conduct experiments and/or point us to relevant literature that our curators may have missed, in order to support these profiles.
When should it be used? These profiles are not non-validated, so we recommend using them with caution.
This collection is a curated repository of interpretable deep learning models designed to predict transcription factor binding preferences. The collection also includes motifs and matrices derived from model interpretation, ensuring compatibility with CORE and UNVALIDATED collections.
When should it be used? When cooperative binding or positional dependencies are relevant, or when predictive modeling is required in conjunction with experimental evidence.